
You have probably heard the term data layer several times when you are looking to explore analytics implementation options for your website. Whilst the term is often used I found that it’s never explained in a way that is understandable to a marketer, often times leaving them confused and unsure of what it is or how they need to go about implementing it. In this article I will run over the basics of what a datalayer is and how it relates to your analytics setup and tracking.
1. The Datalayer is basically a information layer
The datalayer is essentially a layer of information that you want to pass on to google tag manager or other platforms. The data can be pulled in from the servers and placed on each and every page when it loads or when the user interacts in a certain way with the content. For example when a user logs in you can push their user ID or subscription level into the datalayer for tag manager or another platform to pick up. Similarly for an ecommerce store you might push information about what items they are viewing at that time, i.e. product category, price, brand and or where it might be positioned on the page. This is usually achieved by developers writing code that will dynamically pull this information onto your website pages, meaning that some backend coding is required.
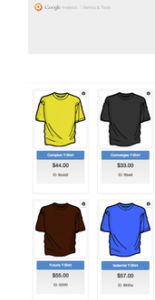
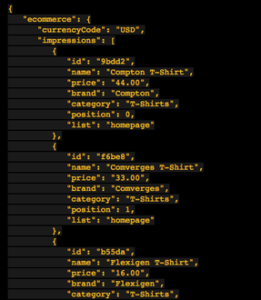
Demo Ecommerce Website and Datalayer Example
2. The datalayer can be more robust and provide a richer data set
Instead of simply tracking things by “scraping data” from certain element id’s and classes etc in the HTML which are prone to break as soon as someone updates a page or changes things, data is dynamically inserted from the server in the backend making it less susceptible to these kind of issues. For example you have a button on your homepage with a particular ID, a tag is setup to fire based on a button click with this particular button id (or class), what this means is that when someone updates the page and is not aware that tags are reliant on this id to pass back data they may change the button id which means you get a breakage in your data collection.
3. The datalayer cannot be implemented without a developer
A downside to using the datalayer often is that businesses lack the expertise or know how of how to implement it. In most cases in order to implement the datalayer you need to have a working knowledge of server side languages as well as access to your backend system, this enables you to pass back those dynamic values to the datalayer for your tags to pick up. I.e. you may want to pass back a page category, subscription level, login status, page errors etc.
4. The datalayer may not be necessary for your business
If you have a smaller website which does not change very often and you do not have the resources on your side that have the necessary skills then a standard analytics implementation will suffice in most cases. From here once a business case has been built and the value of analytics realised it might make sense to start branching out into more advanced implementations which include the datalayer.
5. The datalayer may be necessary if you have a single page application
For certain websites where the page does not refresh or the url does not change it may be necessary to push information like page changes etc to the datalayer in the form of what is called virtual pageviews (vpv’s). Whilst this can be achieved through other methods like firing vpv’s based on next button clicks or history changes etc these usually end up being prone to the same errors as with standard implementations i.e. the slightest page changes could result in tracking breakage.
At the end of the day it really depends on what size business you are, how much you currently use your analytics as well as the resource that may be available on your side for implementation. The datalayer requires planning, resources and time just like a standard implementation and therefore needs to be approached on a case by case basis depending on the business and their capabilities.
Recent Comments